
Wyobraźmy sobie salę wykładową lub dużą konferencję albo posiedzenie zarządu. Jedna osoba coś prezentuje, opowiada, argumentuje. Walczy o uwagę pozostałych, bardzo zajętych uczestników spotkania. Co się dzieje w mózgach tych uczestników? Komunikaty prezentującego docierają do nich dwoma szlakami: wzrokowym i słuchowym. Słyszą zdania, które w ośrodku rozpoznawania mowy są tłumaczone i dalej interpretowane. Analiza języka wymaga energii i skupienia, język jest bardzo abstrakcyjny, ten szlak jest zazwyczaj przeciążony. Obok mamy szlak wzrokowy. W typowych warunkach prezentacji, przyciemniona sala ze światłami skierowanymi na prezentującego, na tym szlaku niewiele się dzieje. Znaczna część mózgu, odpowiedzialna za przetwarzanie obrazu, nudzi się, ponieważ nie jest odpowiednio stymulowana. Wyrazem tego znudzenia jest często przeglądanie poczty lub wykonywanie różnych innych czynności, przy okazji “słuchania” prelegenta.
Ale ten znudzony wzrokowy superkomputer możemy wykorzystać! Dodając graficzną reprezentację informacji, możemy wykorzystać obraz tak, by stał się szkieletem dla naszej prezentacji. Uzupełniające się komunikaty przesłane drogami wzrokową i słuchową zwiększą zrozumienie naszej prezentacji i szansę na zapadnięcie jej w pamięć.
Jednak w życiu nic nie jest za darmo. Szlak wzrokowy to potężny superkomputer, ale też bardzo kapryśny, wybiórczy i trudny do poskromienia. Jest z nami od urodzenia, często więc nawet nie zdajemy sobie sprawy jak bardzo to, co postrzegamy różni się od tego, na co patrzymy. Sposób, w jaki analizujemy obraz, daleki jest od sposobu, w jaki kamera wideo rejestruje obraz na matrycy, a następnie zapisuje na dysku twardym. Ani nasze oko nie działa jak soczewka kamery, ani nasza siatkówka nie działa jak matryca, ani nasz mózg nie działa jak dysk twardy. Mechanizm interpretacji obrazu zakodowany w naszym mózgu ewoluował, aby ułatwić nam poszukiwanie pożywienia i błyskawiczną ochronę przed drapieżnikami, a nie po to, by ułatwiać zrozumienie zależności pomiędzy kolumnami liczb.
Mamy więc superkomputer, który trudno opanować, ale który kryje w sobie olbrzymi potencjał. Jesteśmy jednak profesjonalistami i nie boimy się wyzwań. Dowiemy się jak działa ten superkomputer, dzięki czemu będziemy mogli projektować obraz tak, by był odczytywany w dokładnie taki sposób, w jaki chcemy.
Dobra prezentacja danych to nie wykres przedstawiający poprawnie dane na ekranie komputera, ale wykres przedstawiający poprawnie dane w mózgu odbiorcy.
Zobaczmy więc, w jaki sposób działa stary oszust, czyli nas układ wzrokowy. Przyjrzymy się anatomii mózgu oraz modyfikacjom, którym podlega obserwowany przez nas obraz w miarę jak przechodzi przez kolejne etapy drogi wzrokowej. Będziemy kolejno zaznaczać, jak omawiane zjawisko można przełożyć na lepszą prezentację danych.
 Rysunek 1: W czasie typowej prezentacji komunikaty trafiają do mózgu poprzez słowa i obraz. Źródło: opracowanie na bazie wikipedii
Rysunek 1: W czasie typowej prezentacji komunikaty trafiają do mózgu poprzez słowa i obraz. Źródło: opracowanie na bazie wikipedii
Sprintem przez drogę wzrokową
Zacznijmy od krótkiego omówienia drogi, którą pokonuje obraz. W kolejnych podrozdziałach przyjrzymy się ze szczegółami interesującym fragmentom tej drogi.
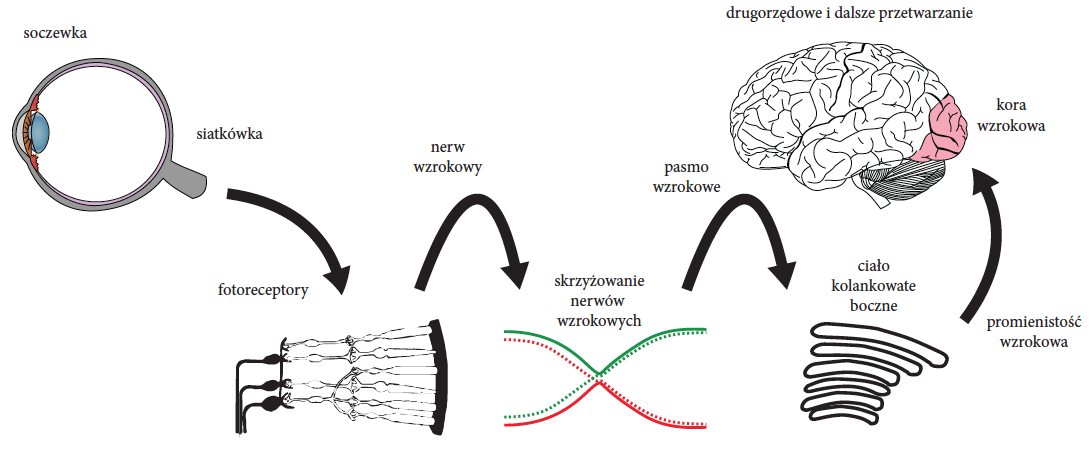 Rysunek 2: Schemat drogi wzrokowej. Po każdym etapie przetwarzania obraz trafia do kolejnych struktur. Źródło: opracowanie na bazie wikipedii
Rysunek 2: Schemat drogi wzrokowej. Po każdym etapie przetwarzania obraz trafia do kolejnych struktur. Źródło: opracowanie na bazie wikipedii
Obraz trafia do naszego oka przez rogówkę, źrenicę i soczewkę. Rogówka i soczewka skupiają światło, rogówka z siłą około 60 dioptrii, soczewka z siłą do 20 dioptrii, choć ta wartość zmienia się z wiekiem. W rezultacie na siatkówkę trafia obraz pomniejszony i odwrócony
Na siatkówce znajduje się kilka rodzajów fotoreceptorów, w tym pręciki i czopki. Te drugie występują w trzech typach o różnej czułości na różne długości fal, dzięki czemu widzimy kolory. Czopki wymagają jednak dobrego oświetlenia do optymalnej pracy. Pręciki pozwalają wyłącznie na widzenie monochromatyczne, ale są bardzo czułe, dzięki czemu jesteśmy w stanie rejestrować obraz przy bardzo słabym oświetleniu. Użycie dwóch rodzajów receptorów pozwala na rejestrowanie obrazu w zakresie jasności rozpinającym się przez dziewięć rzędów wielkości.
Liczba receptorów rejestrujących obraz szacowana jest na 250 milionów, czyli około dziesięciokrotnie więcej niż w przypadku receptorów węchowych, sto razy więcej niż receptorów dotykowych i dziesięć tysięcy razy więcej niż receptorów słuchowych.
Sygnał odczytany przez fotoreceptory jest przekształcany przez kilka warstw komórek dwubiegunowych (łączą się impulsy z wielu receptorów), horyzontalnych (modyfikują sygnały przekazywane z fotoreceptorów do komórek dwubiegunowych), amakrynowych (działanie hamujące już pobudzonych receptorów) oraz zwojowych (selektywnie odbierają różne cechy obrazu, np. kolor, rozmiar, szybkość ruchu). Na tym etapie przetwarzania obrazu wzmacniany jest kontrast, wykrywane są krawędzie i ich orientacja. Następnie sygnał trafia do nerwu wzrokowego, a nim jest transportowany do kolejnych ośrodków przetwarzania.
Na etapie skrzyżowania nerwów wzrokowych obraz jest sortowany tak, by prawa strona widzenia była przetwarzana w prawej półkuli, a lewa w lewej. Następnie przez pasmo wzrokowe obraz trafia do ciała kolankowatego bocznego, gdzie dochodzi do wyróżnienia kolejnych cech obrazu, dalszego przetwarzania i dalszego transportu. Przetworzony obraz trafia przez pasmo włókien nerwowych nazywane promienistością wzrokową do obszaru potylicznego mózgu, w którym dochodzi do dalszego przetwarzania, nazywanego pierwszorzędowym, drugorzędowym i kolejno-rzędowym przetwarzaniem sygnału. Dalej wyróżnia się kilkadziesiąt szlaków odpowiedzialnych za rozmaite aspekty obrazu, takie jak identyfikacja ruchu, lokalizacja obiektów, rozpoznawania obiektów itp.
W tym miejscu obraz jest rozbity na czynniki pierwsze i mózg jest gotów do głębokiej interpretacji obrazu.
Obraz
Ludzkie oko zauważa również różnice w intensywności światła padającego na siatkówkę. Zanim zaczniemy szczegółowo omawiać przetwarzanie tego obrazu przez odbiorcę, przyjrzyjmy się przez chwilę źródłom obrazu i zastanówmy się, jakie czynniki poza samą strukturą wykresu wpływać będą na możliwość jego poprawnego odczytania.
W przypadku grafiki statystycznej trzy typowe źródła obrazu to: świecące diody ekranu komputera (diody świecą aktywnie, na postrzegany obraz światło tła ma niewielki wpływ, znaczny wpływ mają jednak parametry ekranu takie jak rozdzielczość czy kontrast); światło odbite od kartki papieru z nadrukiem grafiki (stopień absorpcji nadruku jest zależny od jakości papieru i jakości tuszy w drukarce, a parametry światła odbitego zależą od oświetlenia, czy jest to światło dzienne, czy nocna lampka); światło odbite od ekranu, na którym wyświetlany jest obraz za pomocą np. rzutnika multimedialnego (parametry absorpcji ekranu są stałe, światło generowane przez projektor jest stałe, ale światło tła może mieć duże znaczenie dla percepcji obrazu).
Przygotowując wykres, musimy zdawać sobie sprawę, że możliwość zauważenia czy rozróżnienia elementów czynnika silnie zależy od użytego medium. Dwa odcienie szarości mogą być lub nie być rozróżnialne na ekranie komputera, a zachowywać się zupełnie inaczej na wydruku.
W przypadku ekranów komputerowych mamy zazwyczaj znacznie większy kontrast obrazu niż w przypadku wydruku, jednak za cenę mniejszej rozdzielczości. Większość współczesnych ekranów komputera ma rozdzielczość w granicach 100–300 pikseli na cal, drukarki laserowe mają rozdzielczość wydruku rzędu 600–2400 punktów na cal
W przypadku wydruku wiele zależy od jakości (jasności i faktury) papieru oraz drukarki (rozdzielczości i techniki nadruku). Nad tym czynnikami często mamy kontrolę. Wiele zależy też od oświetlenia, przy którym wydruk będzie oglądany. Wydruk na papierze o dużym kontraście oglądany przy wystarczająco silnym oświetleniu pozwala na zauważenie większej liczby szczegółów niż wydruk na kredowym papierze z recyklingu oglądany przy nocnej lampce.
Podobnie jest z projekcją obrazu na ekran. Dobry ekran, dobry projektor i odpowiednie zaciemnienie sali pozwalają na zauważenie znacznie większej liczby szczegółów niż słaby projektor, którego obraz wyświetlany jest na ścianie przy dziennym świetle.
Bez względu jednak na to, co jest źródłem obrazu, czy świecący ekran LCD, czy odbijający światło ekran projektora, czy też odbijająca światło słoneczne kartka papieru, początek naszej przygody zaczyna się od chwili, gdy obraz trafia do oka.
Anatomia gałki ocznej
Przyjrzyjmy się teraz bliżej poszczególnym elementom narządu wzroku. Najpierw obraz przechodzi przez rogówkę. Rogówka to przezroczysta tkanka nieposiadającą naczyń krwionośnych (te utrudniałyby widzenie). Rogówka jest silnie unerwiona, reaguje bólem i łzawieniem na dotyk lub ciała obce oraz silnie załamuje światło. Łzy transportują substancje odżywcze, przejmując w rogówce częściowo funkcje układu krwionośnego
Rogówka ma też bardzo silne właściwości skupiające światło o sile około 40 dioptrii, znacznie większe niż soczewka. Ale w przeciwieństwie do soczewki ta wartość nie jest regulowana.
Za rogówką znajduje się tęczówka Ta reguluje ilość światła docierającego do głębszych warstw oka przez rozszerzanie lub zwężanie źrenicy. Z uwagi na obecny w niej barwnik tęczówka odpowiada za kolor oczu. Źrenica, czyli otwór w tęczówce, przez który przepuszczane jest światło, u dorosłej osoby ma szerokość od 2 do 8 milimetrów. Szerokość źrenicy zmienia się w sposób niezależny od naszej woli, zazwyczaj pod wpływem intensywnego światła, ale również w zależności od emocji, substancji chemicznych i innych czynników.
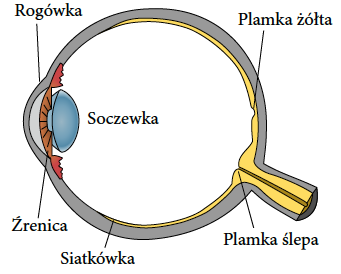 Rysunek 3: Schematyczny przekrój prawego ludzkiego oka w płaszczyźnie poziomej. Na schemacie zaznaczono wybrane elementy gałki ocznej. Źródło: własna modyfikacja schematu z Wikipedii, domena publiczna
Rysunek 3: Schematyczny przekrój prawego ludzkiego oka w płaszczyźnie poziomej. Na schemacie zaznaczono wybrane elementy gałki ocznej. Źródło: własna modyfikacja schematu z Wikipedii, domena publiczna
Szeroka źrenica przepuszcza dużo światła, co jest przydatne przy słabym oświetleniu, wąska źrenica przepuszcza mniej światła, co zapobiega “oślepieniu” fotoreceptorów przy silnym oświetleniu. Zmieniając czterokrotnie średnicę źrenicy można zwiększyć lub zmniejszyć szesnastokrotnie ilość światła, które przechodzi dalej (pole powierzchni źrenicy zależy od kwadratu jej promienia). Zwężanie i rozszerzanie źrenicy następuje dosyć szybko, co ułatwia adaptację do nagłych zmian w oświetleniu.
Po przejściu przez źrenicę obraz przechodzi przez soczewkę. Soczewka to przezroczysta tkanka, która ma silne właściwości skupiające światło. Ponadto jest otoczona ciałem rzęskowym, które za pomocą wiązadełek Zinna zmienia kształt soczewki w zależności od potrzeby, a co za tym idzie zmienia siłę skupiającą światło (co nazywamy akomodacją oka). Współczynnik załamania soczewki zmienia się z wiekiem, również zdolności akomodacyjne soczewki zmieniają się z wiekiem. Począwszy od średnio 20 dioptrii w wieku lat 4, przez 11 dioptrii w wieku lat 20, 3 dioptrie w wieku lat 45 i 1 dioptrię w wieku lat 60. Te dodatkowe dioptrie soczewki są potrzebne by widzieć blisko. Zdolności skupiające rogówki powinny wystarczać by widzieć ostro odległy obraz, ale by widzieć wyraźnie obraz w odległości kilku centymetrów potrzebujemy dodatkowych dioptrii. Dlatego też osoby starsze mają często trudności z czytaniem z bliska bez okularów. Niesie to oczywiste konsekwencje, jeżeli planujemy wykres dla starszych osób to lepiej usunąć z niego zbędne szczegóły. Część osób i tak ich nie zobaczy, a będą tylko przeszkadzały.
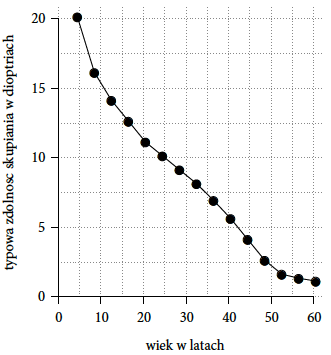 Rysunek 4: Zmiana zdolności akomodacyjnych soczewki z wiekiem. Źródło: opracowanie na bazie wikipedii
Rysunek 4: Zmiana zdolności akomodacyjnych soczewki z wiekiem. Źródło: opracowanie na bazie wikipedii
Za soczewką znajduje się ciało szkliste, czyli galaretowata substancja wypełniająca oko, w większości składająca się z wody. Ściany oka zbudowane są z twardówki, która w części przedniej zamienia się w przezroczystą rogówkę. Tylna ściana oka jest wyścielona przez siatkówkę W siatkówce znajdują się światłoczułe fotoreceptory rejestrujące obraz. To bardzo ważny punkt na drodze obrazu do głębszych rejonów mózgu, dlatego dokładniej mu się przyjrzymy.
W siatkówce znajdują się dwa rodzaje fotoreceptorów: czopki i pręciki (nazwa pochodzi od ich kształtu). Czopków jest około 6–7 milionów, pręcików jest znacznie więcej, około 100–130 milionów. Te dwa typy receptorów różnią się aktywnością, czułością, rozmieszczeniem na siatkówce i pełnią różne funkcje w procesie widzenia.
Sygnał z fotoreceptorów ulega wstępnemu przetworzeniu jeszcze zanim trafi do nerwu wzrokowego. Jednym z przykładów tej wstępnej obróbki jest zjawisko hamowania obocznego.
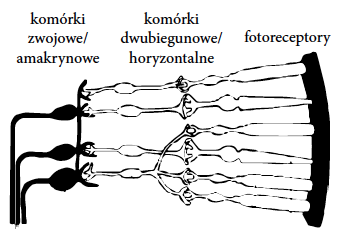 Rysunek 5: Schemat dna oka. Przy zewnętrznej krawędzi znajdują się fotoreceptory, są one połączone z komórkami horyzontalnymi, dwubiegunowymi i zwojowym, które pośredniczą w aktywacji nerwu wzrokowego. Na powyższym schemacie światło biegnie w prawą stronę, aktywowane fotoreceptory przekazują sygnał w lewą stronę.
Rysunek 5: Schemat dna oka. Przy zewnętrznej krawędzi znajdują się fotoreceptory, są one połączone z komórkami horyzontalnymi, dwubiegunowymi i zwojowym, które pośredniczą w aktywacji nerwu wzrokowego. Na powyższym schemacie światło biegnie w prawą stronę, aktywowane fotoreceptory przekazują sygnał w lewą stronę.
Hamowanie oboczne
Hamowanie oboczne, to proces mający na celu zwiększenie kontrastu w pobliżu krawędzi. Lepsze rozpoznawanie krawędzi pozwala na lepsze rozpoznawanie kształtów. Zanim zrozumiemy, w jaki sposób działa ten proces, zobaczmy jego skutki na przykładzie złudzenia optycznego nazywanego pasmami Macha, na cześć ich odkrywcy Ernsta Macha (1838–1916).
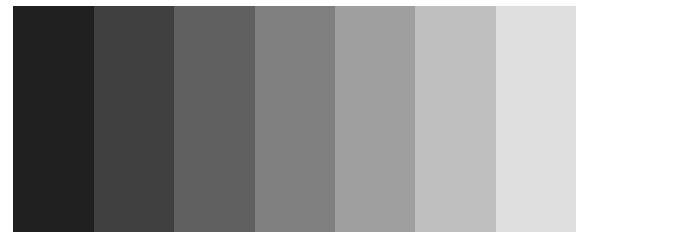
Patrząc na przedstawione powyżej siedem pasów odnosimy wrażenie, że nie są one jednolite. Każdy z pasów wydaje się lekko ciemniejszy po prawej stronie, tam gdzie styka się z jaśniejszym pasem, niż po lewej stronie, tam gdzie styka się pasem ciemniejszym. Jak się wkrótce okaże, zjawisko hamowania obocznego występuje na wielu poziomach drogi wzrokowej. Pokazuje ono, że odbiór elementów graficznych, w tym przypadku stopnia szarości, zależy od obiektów sąsiednich, czyli od kontekstu.
Rysunek 6: Pasma Macha, ilustracja efektu hamowania obocznego. Przedstawiono siedem pasów o jednolitym kolorze. Źródło: opracowanie na bazie wikipedii
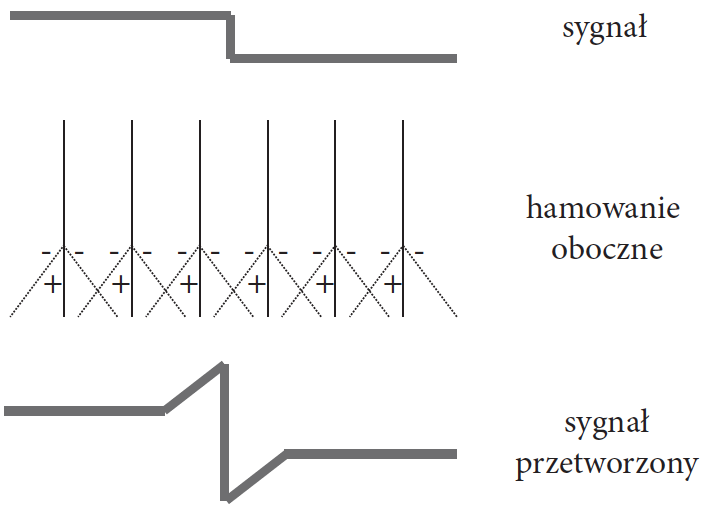
Rysunek 7: Ilustracja mechanizmu hamowania obocznego. Sygnały z sąsiednich neuronów działają jak inhibitory, dzięki czemu uzyskuje się efekt wyostrzonych krawędzie. Szarą linią u góry zaznaczono przebieg oryginalnego sygnału, poniżej jest schematyczna warstwa neuronów, które modyfikują sygnał w zależności od sygnału w neuronach sąsiednich, oraz warstwa sygnału przetworzonego. Źródło: opracowanie własne
Odczyt sygnału z fotoreceptora jest zmodyfikowany przez ujemny wpływ sygnału z sąsiednich fotoreceptorów. Efekt inhibicji jest widoczny w miejscach, gdzie stykają się obiekty różniące jasnością, kolorem, wielkością. Im bliżej styku i im większa różnica, tym wyraźniejszy efekt hamowania.
Przykład powyżej dotyczył stopnia szarości, ale podobne zjawisko powoduje zniekształcenia w postrzeganiu kształtu, wielkości czy koloru. Iluzja Titchenera, nazwana po jej odkrywcy, którym był Edward Bradford Titchener (1867–1927) pokazuje, jak umieszczenie koła w sąsiedztwie większych/mniejszych kół zmienia postrzeganie jego wielkości.
Warto zapamiętać ten przykład, ponieważ na wykresach często za pomocą pól lub długości przedstawiamy różne wielkości liczbowe. A jak widzimy, postrzeganie pól i wielkości może silnie zależeć od wielkości sąsiednich obiektów.

Rysunek 8: Iluzja Titchenera. Koła umieszczone w centrum mają takie same wielkości, są jednak postrzegane jako koła o różnych wielkościach w zależności od tego, w jakim znajdują się otoczeniu. Źródło: opracowanie na bazie wikipedii
Topografia siatkówki
Fotoreceptory rozmieszczone są na siatkówce nierównomiernie. Jeśli przyjmiemy centralny obszar widzenia za punkt zero, to wykres 9 prezentuje jak gęstość upakowania różnych rodzajów fotoreceptorów zależy od odległości od centralnego punktu widzenia.
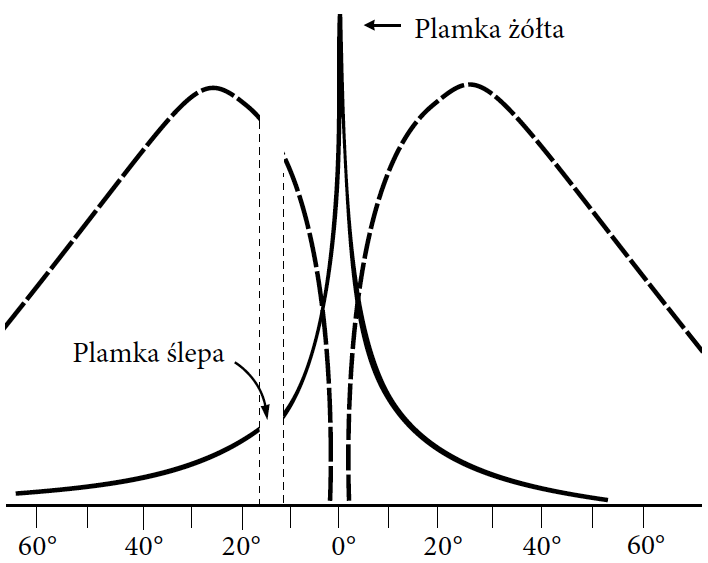
Pierwsza banalna obserwacja jest taka, że gęstość rozłożenia tych fotoreceptorów jest nierównomierna. Szczególnie duże nagromadzenie czopków występuje w centralnym punkcie siatkówki nazywanym plamką żółtą lub dołkiem środkowym (w tym miejscu na siatkówce występuje bowiem zagłębienie, pozwalające na upakowanie jeszcze większej liczby fotoreceptorów). Poza plamką żółtą większość siatkówki wypełniają pręciki. Wyjątkiem jest plamka ślepa, ujście nerwu wzrokowego, miejsce pozbawione zarówno czopków jak i pręcików.
Na poprzednim schemacie połączenia fotoreceptorów z nerwem wzrokowym pokazaliśmy, że nerw wzrokowy zaczyna się bliżej wewnętrznej części oka niż fotoreceptory. Nerw ten musi jednak w którymś miejscu przedostać się przez ściankę twardówki. To miejsce to właśnie plamka ślepa, o wielkości około 1,5 $mm^2$ oddalona o kilkanaście stopni od plamki żółtej.
Osoby słyszące po raz pierwszy o plamce ślepej są często zaskoczone, jak to możliwe, że w obszarze widzenia każdego oka znajduje się obszar, w którym nic nie widzimy. Obraz, który postrzegamy wydaje się być spójny, bez żadnych czarnych dysków odpowiadających ślepej plamce.
Dlaczego nie widzimy, że nie widzimy? Mózg nam pomaga uzupełnić ten obraz i robi to na tyle sprawnie, że najczęściej nie zauważamy żadnego braku. Ale prosty eksperyment pokazuje, jak działa ten stary oszust.
Rysunek 9: Schematyczny profil gęstości receptorów światłoczułych wzdłuż poziomego przekroju siatkówki. Gęstość jest unormowana, by łatwiej było porównać te profile. Należy pamiętać, że pręcików jest kilkanaście razy więcej niż czopków. Linią ciągłą przedstawiono znormalizowane natężenie czopków, linią przerywaną znormalizowane natężenie pręcików w zależności od odległości kątowej od plamki żółtej, która leży w centrum pola widzenia. Natężenie czopków odpowiada ostrości widzenia, która jest najwyższa w dołku środkowym, środku żółtej plamki. Poza centralnym polem widzenia jest znacznie niższa. Zaznaczono też plamkę ślepą, której dotyczy opisywany poniżej eksperyment. Źródło: opracowanie na bazie wikipedii

Przyjrzyj się rysunkowi 10. Zamknij lewe oko, a prawym patrz prosto na kropkę po lewej stronie. Patrząc cały czas na czarną kropkę, przesuwaj powoli kartkę bliżej w kierunku oka. W pewnej odległości (mniej więcej 15 centymetrów) zauważysz, że czarny krzyżyk zniknie choć wciąż powinien znajdować się w polu widzenia. Nie będziesz jednak go widział, ponieważ jego obraz wyświetli się na ślepą plamkę, na której nie ma receptorów. Jeżeli dalej przesuniesz kartkę, krzyżyk znowu pojawi się.
Niesamowite prawda? Jeszcze bardziej niesamowite jest to, że obraz padający na ślepą plamkę nie jest tak po prostu wycinany. Nie jest przecież tak, że cały czas widzimy białą dziurę w polu widzenia. W rzeczywistości obraz jest uzupełniany przez mózg na podstawie jego otoczenia! To znaczy, że mózg samoczynnie “uzupełnia” obraz tak by był “spójny” z otoczeniem. Łatwo to potwierdzić prostym eksperymentem przedstawionym na rysunku 11.
Rysunek 10: Prosty eksperyment pozwalający zaobserwować efekty działania plamki ślepej. Patrząc prawym okiem na lewą kropkę, znajdziemy taką odległość od kartki, że czarny krzyżyk zniknie z pola widzenia
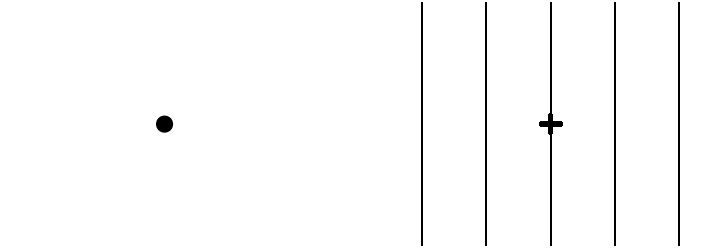
Zamknij lewe oko, a prawe skieruj na czarną kropkę po lewej stronie. Patrząc cały czas na czarną kropkę, przesuwaj powoli kartkę bliżej oka. W pewnej odległości zauważysz, że nie widzisz czarnego krzyżyka,ale wciąż widzisz wszystkie pionowe linie. Obraz krzyżyka pada na ślepą plamkę, ale mózg uzupełnia obraz pionowych linii.
Po przykładzie z hamowaniem obocznym i ślepą plamką, powinno być już oczywiste, że to co widzimy, nie musi być podobne do tego, co jest narysowane. Kolejne etapy przetwarzania obrazu nadpisują to, co fotoreceptory rejestrują. A im głębiej, tym obraz jest bardziej zmieniony.
Rysunek 11: Tym razem, gdy czarny krzyżyk zniknie z obszaru widzenia, zamiast zaobserwować białą plamę, widzimy obraz uzupełniony przez nasz mózg. Jest to przykład ilustrujący, że to, co widzimy, to nie zawsze jest to, co jest narysowane
Pręciki i czopki
Wspomnieliśmy już, że w siatkówce występują dwa rodzaje fotoreceptorów, czopki i pręciki, które różnią się znacząco w sposobie działania. Za aktywność pręcików odpowiedzialny jest barwnik rodopsyna, bardzo czuły, tak czuły, że do jego aktywacji w optymalnych warunkach wystarczy pojedynczy foton. Pręciki mają dużą czułość wychwytywania sygnałów, ale ponieważ sygnał jest sumowany z wielu pręcików, otrzymuje się sygnał o małej rozdzielczości. Reakcja pręcików na światło jest wolna. Pojedynczy cykl widzenia składający się ze zmiany formy receptora pod wpływem impulsu świetlnego i powrocie do formy wyjściowej trwa długo, około 0,1 sekundy. Jeżeli jakiś przedmiot przemieszcza się szybko na granicy pola widzenia, to trudno będzie go śledzić. Samą obecność jakiegoś ruchu jednak szybko wykryjemy.
Za aktywność czopków odpowiada jodopsyna, która do pobudzenia wymaga około 100 fotonów, jest więc znacznie mniej czuła. Jodopsyna ma krótszy cykl widzenia, szybciej reaguje na światło, o ile jest ono wystarczająco silne. Okres sumowania sygnałów z czopków jest dziesięciokrotnie krótszy od okresu sumowania z pręcików i wynosi w przybliżeniu 0,01 sekundy (najszybciej reagują czopki “czerwone” najczulsze dla fal długich, najwolniej czopki “niebieskie” najczulsze dla fal krótkich). Pręcików w siatkówce jest około 100–130 milionów, a czopków “tylko” 6–7 milionów. Czułość czopków zmniejsza się również z wiekiem.
Podsumowując, czopki pozwalają na widzenie ostre, z możliwością śledzenia poruszających się obiektów, ale jedynie przy dobrym oświetleniu. Pręciki są bardzo czułe, ale reagują wolniej, obraz ma małą rozdzielczość, przez co trudniej śledzić ruch.
Na rozdzielczość widzenia wpływa również liczba receptorów na jedną komórkę nerwową, która przenosi sygnał. W przypadku czopków w centralnym polu widzenia na jeden czopek może przypadać jeden nerw. Na skrajnych obszarach siatkówki rozdzielczość jest znacznie niższa, kilkaset pręcików może być połączonych z jedną komórką nerwową. Każdy z pręcików może aktywować impuls w tym nerwie, ale rozdzielczość będzie niska, ponieważ mózg nie będzie wiedział, który z pręcików ten sygnał zarejestrował.
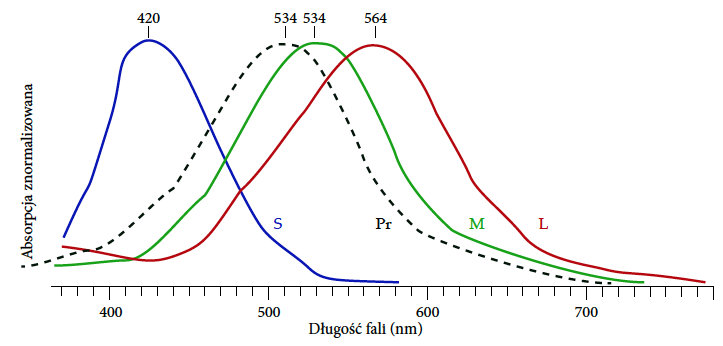
W naszym oku występują czopki z trzema różnymi typami jodopsyny, nazywane typami S (od ang. short), M (od ang. medium) i L (od ang. long) w zależności od tego, na jaką długość fali są najbardziej czułe. Czopki typu S najsilniej reagują na fale krótkie, przez co kojarzone są z rozpoznawaniem niebieskiego koloru. Czopki M i L reagują najsilniej odpowiednio na fale średnie i długie, przez co zwyczajowo kojarzy się je z rozpoznawaniem kolorów zielonego i czerwonego.
Rysunek 12: Znormalizowany profil absorpcji różnych typów czopków (Long, Medium i Short) oraz achromatycznych pręcików (Pr). Źródło: opracowanie na bazie wikipedii
Interesującym miejscem na siatkówce jest plamka żółta. Jest to obszar o zwiększonej gęstości czopków, który odpowiada wysokiej ostrości widzenia w polu o szerokości około 10 stopni (mniej więcej obszar o rozpiętości tej, która odpowiada obrazowi tarczy Księżyca). W samym środku żółtej plamki znajduje się dołek środkowy o szerokości około 5 stopni, w którym nagromadzenie czopków jest największe. Nagromadzenie czopków odpowiada ostrości widzenia, dlatego też największa ostrość widzenia dotyczy niewielkiego obszaru w centralnym polu widzenia.
To również może wydawać się zaskakujące, ale wyraźnie i ostro widzimy tylko wąskim okienkiem umieszczonym w środku pola widzenia. Gdy patrzymy na klawiaturę oko rejestruje wyraźnie obraz litery z jednego, maksymalnie kilku klawiszy, wydaje się nam jednak, że widzimy wyraźnie wszystkie litery, ponieważ gałka oczna skanuje otoczenie i uzupełnia w naszym mózgu opis obiektu znajdującego się w danym miejscu.
 Rysunek 13: Zewnętrzne koło obserwowane z odległości około 60 cm (w przybliżeniu odległość od barku do nadgarstka dla osoby o wzroście 180 cm) obejmuje kąt 10 stopni. Wewnętrzne odpowiada kątowi 5 stopni. Taki obszar widzimy na tyle ostro, by rozróżniać litery. Źródło: opracowanie własne
Rysunek 13: Zewnętrzne koło obserwowane z odległości około 60 cm (w przybliżeniu odległość od barku do nadgarstka dla osoby o wzroście 180 cm) obejmuje kąt 10 stopni. Wewnętrzne odpowiada kątowi 5 stopni. Taki obszar widzimy na tyle ostro, by rozróżniać litery. Źródło: opracowanie własne
Widzenie fotopowe, mezopowe i skotopowe
Od oświetlenia zależy zarówno rozdzielczość widzenia, jak i obszar kątowy, w którym widzimy wyraźnie. Z uwagi na dużą czułość pręcików, są one wyłączane przy silnym świetle. Z drugiej strony z uwagi na małą czułość czopków, nie działają one przy słabym świetle. Przyjmuje się, że przy natężeniu oświetlenia przekraczającym $1$ kadnelę na metr kwadratowy oko ludzkie działa w trybie widzenia dziennego, tzw. fotopowego, opartego wyłącznie na czopkach (zapewniających widzenie barwne).
Przy słabym świetle, poniżej 0,01 kandeli na metr kwadratowy, oko działa w trybie widzenia nocnego, tzw. skotopowego, opartego wyłącznie na pręcikach, a tym samym pozbawionego barw. W obszarze przejściowym działają częściowo zarówno pręciki jak i czopki i mówimy o widzeniu mezopowym/zmierzchowym (stan pośredni pomiędzy światem barwnym a postrzeganym wyłącznie w barwach szarości). Granica na poziomie 0,01 i 1 kandeli na metr kwadratowy jest pewnym uśrednieniem. W różnych źródłach literaturowych rozbieżności pomiędzy tymi granicami przekraczają rząd wielkości.
Zaskakujące jest w jak szerokim spektrum oświetlenia pracuje nasze oko. System składający się z czułych na niskie światło pręcików i trudnych na wysycenia czopków pozwala na rejestracje obrazu w zakresie jasności obejmujących dziewięć rzędów wielkości! Pewną zasługę ma w tym adaptująca się źrenica, pozwalająca na wpuszczenie do oka kilkunastu razy więcej lub mniej światła, ale głównie jest to zasługa dwóch rodzajów receptorów.
To, że wzrok może pracować w warunkach oświetleniowych różniących się o dziewięć rzędów wielkości, nie oznacza, że jednocześnie jesteśmy w stanie obserwować taki szeroki zakres. Oko dostosowuje się do średniego oświetlenia w danym momencie (oświetlenie tła) i w dobrych warunkach jest w stanie rejestrować różnice w jasności sąsiednich pól z rozdzielczością różnic sięgającą 1% jasności. Dostosowując się do średniego oświetlenia, w jednej chwili oko potrafi przypisywać gradacje stopni jasności w zakresie dwóch rzędów wielkości.
Ponieważ przy dziennym oświetleniu nie działają pręciki, zakres kątowy widzenia jest znacznie węższy niż przy niskim świetle. Przy niskim oświetleniu znacznie spada rozdzielczość widzenia, z trudnością przychodzi czytanie (rozróżnianie liter) czy rozróżnianie kształtów. Również przy niskim świetle, gdy czopki są nieaktywne, plamka żółta zachowuje się tak samo jak plamka ślepa, ponieważ są tam praktycznie wyłącznie czopki. Dlatego w nocy nie widzimy wyraźnie obszaru centralnie na wprost kierunku patrzenia.
Pełna aktywacja systemu widzenia nocnego, pozwalająca na rejestrację obrazu przy bezksiężycowym zachmurzonym niebie, może trwać do pół godziny. W warunkach miejskich, nawet w nocy, światła jest znacznie więcej, ale wciąż nocą w pokoju po wyłączeniu oświetlenia system widzenia skotopowego potrzebuje czasu, by zaczął w pełni funkcjonować
Aktywacja widzenia dziennego jest szybsza. Szybkie przejście z ciemnej jaskini w pełne słoneczne światło może być odrobinę bolesne, póki nie wyłączy się oślepiony system widzenia nocnego, ale system widzenia dziennego działa praktycznie natychmiast.
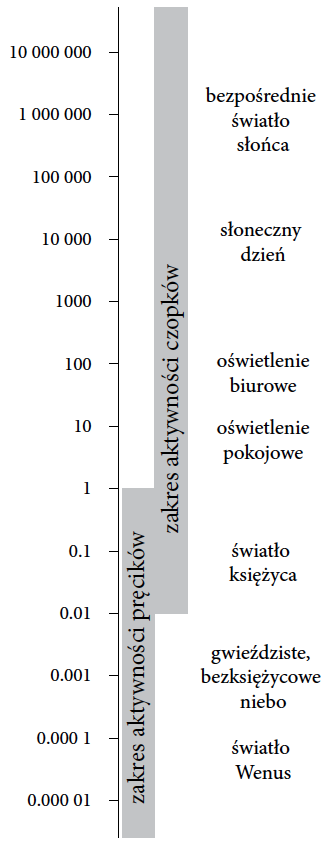 Rysunek 14: Wartość luminancji białej kartki papieru oświetlonej określonym źródłem światła w kandelach na metr kwadratowy. Źródło: opracowanie na bazie wikipedii
Rysunek 14: Wartość luminancji białej kartki papieru oświetlonej określonym źródłem światła w kandelach na metr kwadratowy. Źródło: opracowanie na bazie wikipedii
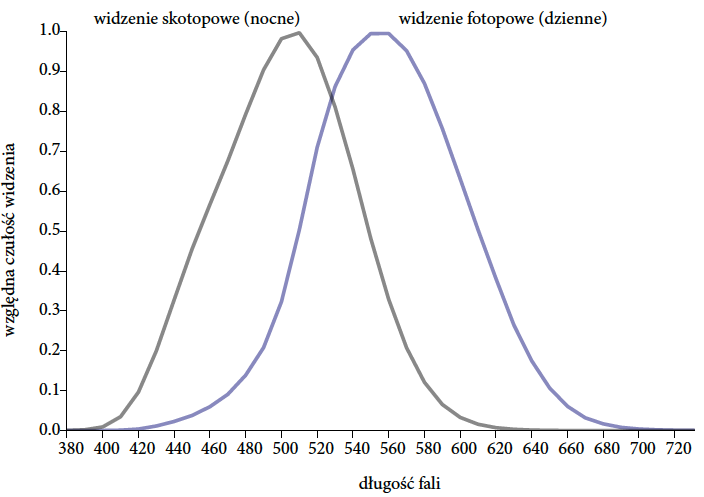
Czułość czopków i pręcików na różne długości fali jest różna. W dziennym systemie widzenia fale długie, odpowiadające odcieniom koloru czerwonego są widziane z dużą czułością. W systemie widzenia nocnego, są już znacznie słabiej rejestrowane, przez co podczas zmierzchu odczuwalna jest różnica we względnej widoczności/postrzeganej jasności koloru czerwonego (dobrze widzianego przez czopki, a słabo przez pręciki). Efekt ten nazywany jest zjawiskiem Purkiniego. Czasem przypisuje mu się zwiększoną liczbę stłuczek z udziałem czerwonych samochodowych podczas zmierzchu. W dobrym oświetleniu czerwone auta są świetnie widoczne i stłuczek z ich udziałem jest mało, przy widzeniu mezopowym (zmierzchowym) czerwony przestaje być wyróżniającym się kolorem.
Zarówno rozdzielczość widzenia, jak i zdolność do rozpoznawania kolorów, zależą od stopnia oświetlenia oraz odległości od centralnego pola widzenia. Obszar, w którym widzimy wyraźnie jest, bardzo wąski. W przypadku tekstu standardowej wielkości oglądanego ze standardowej odległości wynosi on około kilkunastu liter.
Zaskakujące? Patrząc na tę stronę tekstu z pewnością nie mamy wrażenia, że wszystko poza tym jednym wyrazem, na którym patrzymy jest rozmyte. Ale łatwo to pokazać doświadczalnie. Wystarczy skoncentrować wzrok na jednym wyrazie i utrzymując wzrok na tym wyrazie, odczytać tekst znajdujący się kilka linii niżej bez przenoszenia wzroku. To nie będzie możliwe. Mamy wrażenie ostrych liter, ale ich nie odczytamy póki nie skierujemy na nie wzroku, bo ostrość jest tylko wrażeniem.
Rysunek 15: Względna czułość reakcji czopków i pręcików na różne długości fali. Źródło: opracowanie na bazie wikipedii
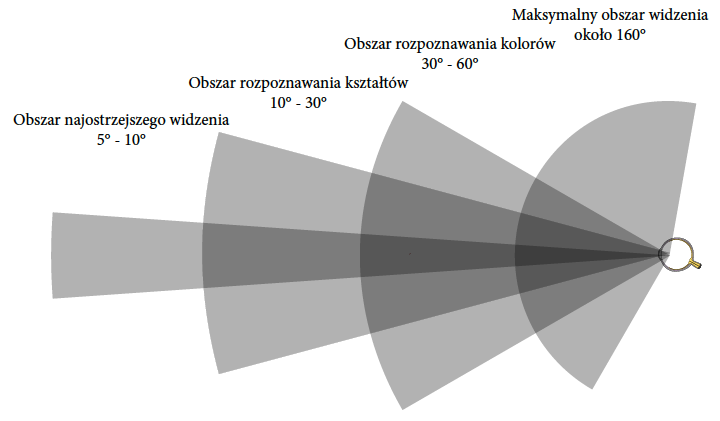
Na rysunku 16 jest przedstawiony zakres widzenia z zadaną precyzją w warunkach dobrego oświetlenia. Zakres widzenia jednego oka wynosi od -60 stopni do 105 stopni, asymetrycznie, ponieważ część pola widzenia jest zasłonięta przez nos. Maksymalny obszar widzenia obuocznego obejmuje około 120 stopni a całkowity obszar widzenia to ponad 200 stopni. Na brzegach siatkówki niewiele jest jednak czopków, przez co w dzień szerokość pola widzenia jest mniejsza.
Rysunek 16: Obszar widzenia o różnej ostrości dla jednego oka. Z uwagi na różne rozłożenie gęstości czopków i pręcików obszar, w którym jesteśmy w stanie rozpoznawać kolory, kształty, widzimy wyraźnie, jest silnie zróżnicowany. Obszar, w którym widzimy na tyle wyraźnie, by rozróżniać litery jest bardzo wąski. Ogólne wyobrażenie dotyczące kształtów mamy w szerszym polu widzenia. Rozdzielczość na horyzoncie widzenia jest bardzo niska, zauważymy tam ruch, ale jeżeli nie skierujemy tam wzroku, nie dowiemy się co się poruszyło. Źródło: opracowanie na bazie wikipedii

Zastanówmy się teraz, jakie konsekwencje ma takie wąskie pole widzenia dla grafiki statystycznej. Jeżeli prezentujemy zależność na dwóch sąsiednich wykresach i chcemy tę zależność porównać pomiędzy wykresami, musimy nieustannie tym oknem widzenia ostrego skakać pomiędzy jednym i drugim wykresem, co nie jest wygodne i utrudnia dokładne porównania. Nie jesteśmy w stanie objąć wzrokiem obu wykresów, nasze oko nie ma takiej możliwości. Jeżeli więc chcemy porównać długości, kąty, pola dwóch obiektów, to im bliżej siebie będą te dwa obiekty, tym łatwiejsze zadanie mamy do wykonania.
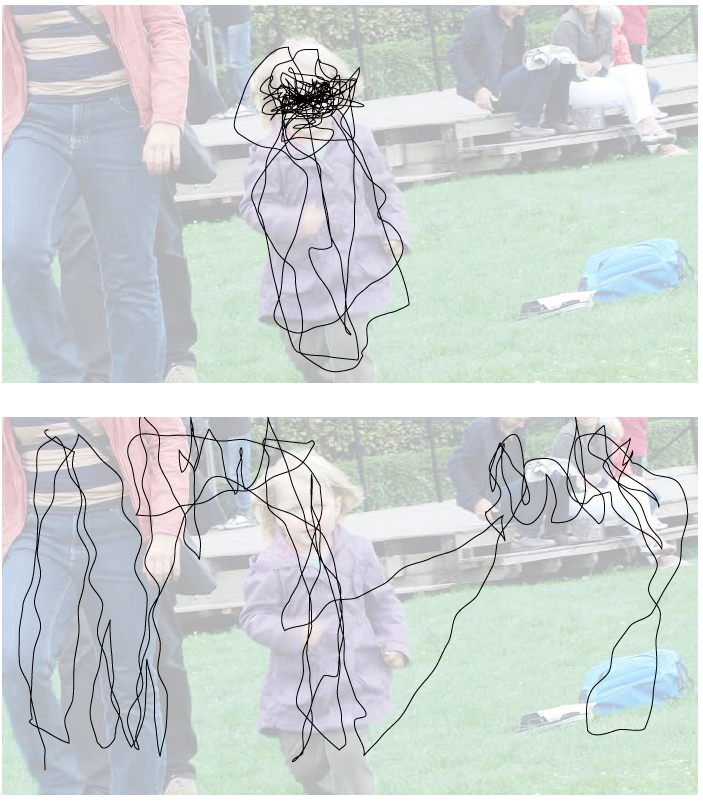
Rysunek 17: Na górnym panelu zdjęcie biegnącej dziewczynki. Na dolnym panelu schematyczny obraz rejestrowany przez fotoreceptory siatkówki. Zarówno ostrość widzenia jak i~postrzeganie kolorów zależą od odległości żółtej plamki na ścianie siatkówki. Obraz blisko centralnego pola widzenia jest widziany z~dużą ilością szczegółów. Im dalej, tym zdolność do rozróżniania kolorów jak i~ostrość widzenia maleją. Źródło: opracowanie własne
Fiksacje i sakady
Wiemy już, że wyraźnie widzimy tylko w wąskim polu widzenia. Bez względu na to, jak bogaty w szczegóły jest wykres, jeżeli to wąskie pole widzenia nie zostanie skierowane na interesujący nas element, to nie zostanie on dostrzeżony. Jeżeli chcemy, by coś zostało zauważone, to powinniśmy zatroszczyć się o to, by nasze oko i nasza uwaga zostały w to konkretne miejsce skierowane.
Gałka oczna nieustannie wykonuje ruch. Czasami na tyle mały, że prawie niewidoczny, ale nieustanny
Musi tak się dziać, ponieważ do nerwu wzrokowego trafiają informacje o zmianie natężenia światła padającego na fotoreceptor. Gdyby gałka oczna się nie ruszała i nie byłoby zmiany w obrazie, to nic byśmy nie rejestrowali.
Ruch gałek oczny podzielony jest na dwie fazy. Jedna z nich to fiksacje (ang. fixation), gdy nasze oko skoncentrowane jest przez 0,2–0,4 sekundy na określonym punkcie (pomijając mikroprzeskoki), w tym czasie mózg rejestruje interesujące go szczegóły. Fiksacje rozdzielone są krótkimi przeskokami nazywanymi sakadami (ang. saccade) .
Rysunek 17 pokazuje schematycznie, jak wygląda obraz rejestrowany przez siatkówkę w czasie pojedynczej fiksacji. Obszar, w którym widzimy kolory jest ograniczony, ale jeszcze bardziej ograniczony jest obszar, w którym widzimy ostro.
To, co zobaczymy na zdjęciu, zależy od tego, na co skierowane będzie oko. Ruch gałek ocznych jest silnie związany z naszą uwagą i pytaniem poznawczym, na które mózg stara się odpowiedzieć. Okazuje się, że te ruchy można śledzić, rejestrować i analizować
Dziś badania ruchu gałek ocznych (badania okulograficzne) przeprowadza się przy okazji wielu zagadnień, czy to rozplanowania elementów strony internetowej (optymalizacja czasu dotarcia do określonej informacji), plakatu reklamującego pieluszki (rozplanowanie elementów plakatu tak, by skierować wzrok obserwatora na logo firmy), czy badań na kierowcach samochodów w celu określenia na jakich elementach drogi wzrok skupiają zaawansowani, a na jakich początkujący kierowcy (początkujący kierowcy powodują więcej kolizji, ponieważ śledzą wzrokiem zbyt mały obszar drogi, często niedostosowany do prędkości i ich czasu reakcji).
Z punktu widzenia wizualizacji danych zależność pomiędzy tym, na czym koncentrowana jest uwaga oglądającego wizualizację, a tym samym na czym koncentrowane są gałki oczne, a pytaniem poznawczym, na które obserwator stara się odpowiedzieć, jest bardzo ważna. Czytając tekst, nasze gałki oczne fiksują się na początkach wyrazów lub innych elementach zawierających ważną dla treści informację. Co jest tym ważnym elementem tekstu zależy od języka. Jeżeli końcówki fleksyjne wyrazu nie pełnią znacznej roli w zrozumieniu tekstu, to wzrok nie będzie się na nich koncentrował.
Alfred Yarbus (1914–1986) przeprowadził wiele bardzo ciekawych badań dotyczących zależności pomiędzy pytaniem poznawczym, a obszarami, na które kierowane jest nasze widzenie. Fascynujący opis tych badań można znaleźć w jego książce Eye Movements and Vision [Alfred Lukyanovich Yarbus. Eye Movements and Vision New York: Plenum, 1967] Na rysunku 18 przedstawiamy schematy dwóch strategii skanowania obszaru przez ludzkie oko, w zależności od pytania, które zostało zadane obserwującemu.
Jak wiedza o strategiach przeglądania obrazu może pomóc w przygotowaniu lepszej prezentacji danych? Jeżeli wykres jest bogaty w szczegóły, to należy poświęcić trochę uwagi, by zastanowić się, co zrobić, by ważne elementy zostały zauważone. Im więcej informacji, tym ważniejsze jest, by informacja była przedstawiana warstwowo. Analizując informację z pierwszej warstwy, mózg jest odpowiednio torowany (czyli przygotowywany, uprzedzany), by wiedział jakiej informacji szukać w kolejnej warstwie. Jeżeli wykresowi towarzyszy słowna prezentacja, to warto powiedzieć, gdzie są interesujące elementy, ułatwi to ich lokalizację. Tytuł wykresu bardzo pomaga, ponieważ wstępnie informuje percepcję, czego wykres dotyczy i ułatwia wybór elementów wykresu do obserwacji.
Oczywiście wiele też zależy od tego, ile czasu odbiorca poświęci na analizę wykresu. Jeżeli kartkuje raport i na analizę wykresu ma kilka sekund, wtedy każda dodatkowa pomoc się liczy. Jeżeli wykres jest częścią wystawy dzieł sztuki i odbiorca poświeci mu więcej czasu, licząc na element zaskoczenia wywołany samodzielnym odkryciem jakiejś zależności (“efekt acha”), możemy być mniej dosłowni w kierowaniu uwagi odbiorcy.
Rysunek 18: Różne strategie skanowania obrazu w zależności od pytania analitycznego zadanego obserwatorowi. W przypadku górnego panelu obserwatora poproszono o zapamiętanie jak największej liczby szczegółów dotyczących biegnącej dziewczynki. Uwaga koncentruje się na elementach charakterystycznych, takich jak cechy ubrania, wzrost, ale przede wszystkim rysy twarzy. W przypadku dolnego panelu obserwatora poproszono o określenie ile i jakie osoby znajdują się na zdjęciu. Widzimy, że wzrok pokrywa inny obszar niż poprzednio. Uwaga została skupiona również na osobach częściowo widocznych, by z dostępnych szczegółów wywnioskować o nich jak najwięcej. Źródło: opracowanie własne
Dalsze przetwarzanie obrazu
Wiemy już, że sygnały z komórek amakrytowych z fotoreceptorów trafiają następnie do skrzyżowania nerwów wzrokowych. W tym miejscu obraz jest sortowany tak, że lewe pole widzenia będzie dalej analizowane przez jedną półkulę, a prawe przez drugą. Przestrzenne położenie neuronów odpowiada wciąż względnemu położeniu neuronów na siatkówce.
Po posortowaniu obraz trafia do ciała kolankowatego bocznego (ang. lateral geniculate nucleus). W tym miejscu dochodzi do dalszego przetwarzania obrazu. Ciało kolankowate boczne zbudowane jest z sześciu warstw różniących się morfologią i funkcją. Dwie pierwsze warstwy, składające się głównie z dużych komórek typu M (łac. Magna znaczy duży), nazywane są warstwami wielkokomórkowymi. Odpowiadają one za identyfikację głębi oraz ruchu. Cechują się krótkim czasem odpowiedzi. Wyjścia tych komórek w dużej części kończą się w szlakach dalszego przetwarzania obrazu związanych z odpowiedzią na pytanie “gdzie”.
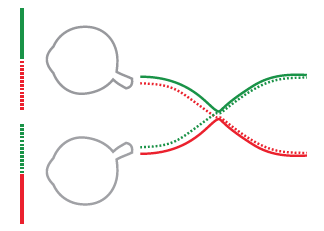 Rysunek 19: Schemat skrzyżowania nerwów wzrokowych. Na tym etapie neurony są “sortowane”. Obraz z prawego pola widzenia obu oczu trafi do jednej półkuli, obraz z lewego pola widzenia trafi do drugiej. Źródło: opracowanie na bazie wikipedii
Rysunek 19: Schemat skrzyżowania nerwów wzrokowych. Na tym etapie neurony są “sortowane”. Obraz z prawego pola widzenia obu oczu trafi do jednej półkuli, obraz z lewego pola widzenia trafi do drugiej. Źródło: opracowanie na bazie wikipedii
Kolejne cztery warstwy składają się głównie z małych komórek typu P (łac. Parvus znaczy mały), nazywane są warstwami drobnokomórkowymi. Zajmują się identyfikacją koloru, głównie z czopków czułych na fale średnie i długie, oraz kształtu. Wyjścia z tych komórek trafiają później do szlaków dalszego przetwarzania obrazu związanych z odpowiedzią na pytanie “co”. Komórki typu P oraz komórki typu M różnią się czasem reakcji (typu M są szybsze) oraz gęstością połączeń.
Dalsze przetwarzanie ma miejsce w korze wzrokowej w płacie potylicznym. W tym miejscu obraz jest dalej analizowany pod kątem konkretnych zadań poznawczych, analizy kontrastu, reakcji na ruch, rozpoznawania twarzy. Po przejściu przez pierwotną korę wzrokową (oznaczaną V1) obraz trafia do wtórnej kory wzrokowej (oznaczanej V2), a następnie do kolejnych pól. Obecnie wyróżnia się około 40 funkcyjnych szlaków przetwarzania obrazu, które z grubsza można podzielić na dwie grupy: odpowiadające na pytania “co” i “gdzie”.
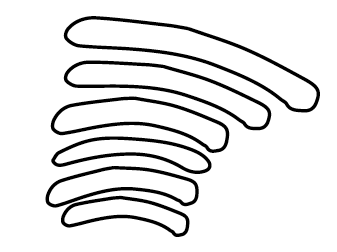 Rysunek 20: Schemat warstwowej budowy ciała kolankowatego bocznego. Źródło: opracowanie na bazie wikipedii
Rysunek 20: Schemat warstwowej budowy ciała kolankowatego bocznego. Źródło: opracowanie na bazie wikipedii
Warto w tym miejscu zaznaczyć, że pomiędzy ciałem kolankowatym bocznym a korą wzrokową istnieje silne sprzężenie zwrotne. Szacuje się, że do ciała kolankowatego trafia 10 razy więcej połączeń nerwowych z potylicznego płatu kory mózgowej niż z fotoreceptorów. Przetwarzanie obrazu w tym miejscu zależy nie tylko od tego, co widzimy teraz, ale też od tego, co widzieliśmy wcześniej!
Dwie informacje są w tym miejscu warte zapamiętania i wykorzystania. Jedna jest taka, że pewne charakterystyki obrazu są rozpoznawane niezależnie. Takie informacje jak kształt, kolor czy położenie są przetwarzane w innych miejscach, przez co nadają się jako nośniki zmiennych, które chcemy przedstawić niezależnie. Przykładowo na jednym wykresie możemy jedne cechy opisywać kształtem, inne kolorem, a jeszcze inne położeniem w układzie współrzędnych. Z drugiej strony pewne charakterystyki, takie jak intensywność i wielkość, przetwarzane są tym samym kanałem, przez co obszary o dużej intensywności, np. jasnoczerwone lub śnieżnobiałe, będą postrzegane jako obszary o większej powierzchni niż czarne. Takich par nie powinniśmy wykorzystywać do przedstawiania różnych zmiennych, ponieważ będą wzajemnie zaburzać swoje postrzeganie.
Druga lekcja jest taka, że na szlaku wzrokowym ma miejsce nieustanna edycja obrazu. Na wielu etapach dochodzi do zwiększenia kontrastu pomiędzy elementami obrazu. Prowadzi to przekłamań w odbiorze obrazu, postrzeganiu iluzji obrazu, którego nie ma. Nie jest dobrze, by takie iluzje obrazu pojawiały się w sposób niekontrolowany. Wielu z tych iluzji można uniknąć, stosując się do kilku prostych zaleceń, o których napiszemy w dalszych podrozdziałach.
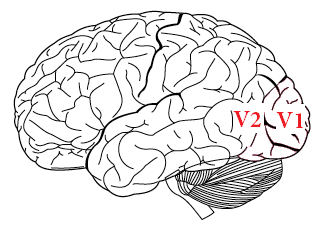 Rysunek 21: Lokalizacja kory wzrokowej w płacie potylicznym mózgu. Źródło: Gray's Anatomy, domena publiczna
Rysunek 21: Lokalizacja kory wzrokowej w płacie potylicznym mózgu. Źródło: Gray's Anatomy, domena publiczna
Iluzje
Nasz mózg w procesie ewolucji mniej troszczył się o to, byśmy potrafili ocenić względne wielkości, niż o to, byśmy szybko wykryli niebezpieczeństwo. Zwiększenie kontrastu pozwala szybciej zauważyć drapieżnika ukrytego w trawie, utrudnia jednak dokładne odczytywanie względnych wielkości na wykresie, szczególnie, gdy dotyczą obiektów położonych daleko od siebie. Lepiej zauważyć zarys lwa w chmurze losowych krzywych, niż przegapić prawdziwego drapieżnika polującego na nas. Jest to jeden z powodów, dla których nasz mózg tak uporczywie stara się znaleźć wzorce w tym, na co patrzymy.
Pierwsza grupa iluzji, o których powiemy, dotyczy widzenia tego, czego nie ma. Im bardziej skomplikowany wykres, tym większa szansa, że coś przypadkowego zostanie uznane za ten “istotny” wzorzec. Tak działa nasz mózg, doszukuje się wzorców, gdzie tylko się da.
Łatwiej jest przyjąć mózgowi, że na rysunku 22 widzi biały kwadrat ponad czterema czarnymi kółkami, niż że widzi cztery bardziej skomplikowane figury jakimi są 3/4 koła (w przyrodzie jest więcej kół i kwadratów niż wycinków 3/4 kół). Dzieje się tak, mimo że zdajemy sobie sprawę z całkowitej abstrakcji obrazu. To nie jest zdjęcie prawdziwych obiektów, nie musimy więc szukać żadnych analogii do rzeczywistego świata. Niemniej jednak nasz mózg został właśnie przystosowany do szukania tych analogii i dlatego na tym wykresie widzimy cztery koła częściowo przysłonięte białym kwadratem.
 Rysunek 22: Czy to cztery czarne koła pod białym kwadratem, czy cztery wycinki koła? Źródło: opracowanie na bazie wikipedii
Rysunek 22: Czy to cztery czarne koła pod białym kwadratem, czy cztery wycinki koła? Źródło: opracowanie na bazie wikipedii
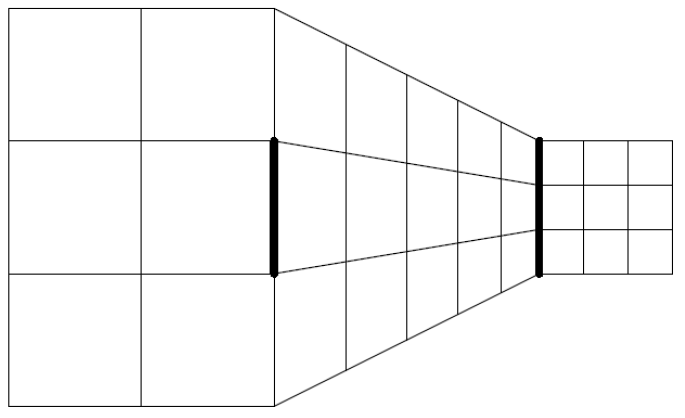
Podobnie ma się sytuacja z pseudo perspektywą. Widząc zdjęcia, spodziewać się możemy, że zdjęcie trójwymiarowego obiektu może przedstawiać perspektywę. Ale nawet w przypadku bardzo abstrakcyjnych rysunków, w których występują elementy tylko sugerujące perspektywę, nasz umysł będzie modyfikował ocenę wielkości, zakładając występowanie perspektywy nawet w sytuacjach, gdzie żadną miarą nie może być mowy o prawdziwej perspektywie. W oczywisty sposób zakłóca to ocenę wielkości.
Jeżeli na wykresie znajdzie się cokolwiek, co może zasugerować mózgowi perspektywę, ta perspektywa będzie dostrzeżona. Automatycznie wpłynie to na zniekształconą ocenę wielkości. Dlatego wszelkim trójwymiarowym wykresom, czy to kołowym, słupkowym czy piramidowym powinniśmy zdecydowanie powiedzieć: NIE
Rysunek 23: Oba pogrubione odcinki mają tę samą długość. Ukośne linie sugerują jednak perspektywę, przez którą odbieramy je jako odcinki o różnej długości. Źródło: domena publiczna

Co ciekawe, wrażenie perspektywy jest tak silne, że dominuje nad analityczną częścią naszego umysłu. Bardzo dobitnym przykładem ilustrującym tę iluzję jest pokój Amesa (patrz rysunek 24). Iluzja została nazwana tak na cześć swojego odkrywcy Adelberta Amesa Juniora (1880–1955). Polega na umieszczeniu osób w różnych miejscach specjalnie zbudowanego pomieszczenia w kształcie trapezu, które z zewnątrz wygląda na prostokątne. W tym przypadku mamy do czynienia wyłącznie z fizycznymi obiektami w rzeczywistym świecie, nie ma miejsca na żadne sztuczki wykonane programem graficznym. Jesteśmy całkowicie świadomi, że musimy obserwować obiekt o tym samym rozmiarze, ponieważ jest to ta sama osoba, a jednak nie potrafimy oprzeć się wrażeniu, że obiekt ma różną wielkość w zależności od tego, w którym miejscu pokoju stoi.
Jest już dla nas jasne, że w zależności od elementów nas otaczających oceny pewnych wielkości mogą być zawyżane lub zaniżane. Innymi słowy możemy sprawić by linia, słupek, wycinek koła na wykresie wydał się mniejszy lub większy, umieszczając w jego sąsiedztwie odpowiednio dobrane elementy.
Problem w ocenie wielkości nie jest spowodowany wyłącznie kontekstem czy nieistniejącą perspektywą. Pewnych charakterystyk po prostu nasz mózg nie jest w stanie dobrze ocenić. Świetnym przykładem są kąty. Jesteśmy w stanie z dużą dokładnością ocenić, czy kąt jest bliski kątowi prostemu, ale mamy duże problemy z oceną wielkości kątów ostrych i rozwartych. Nasz mózg ma skłonność do zawyżania wielkości kątków ostrych i zaniżania kątów rozwartych.
Rysunek 24: Pokój Amesa. Iluzja zbudowana w fizycznym świecie. Wiedząc, że obserwujemy ten sam obiekt nie sposób oprzeć się wrażeniu, że obiekt rośnie lub maleje, gdy przemieszcza się z jednego punktu do drugiego. Źródło: kolaż zdjęć z wystawy Centrum Nauki Kopernik
Ciekawą ilustracją tej skłonności jest iluzja opisana przez Johanna Poggendorffa (1796–1877). Na rysunku 25 linia widoczna po lewej stronie prostokąta jest przedłużeniem jednej z linii widocznych po prawej stronie. Której?
W tym paradoksie, oceniając kąt pomiędzy lewym odcinkiem a szarym prostokątem, nasz mózg ma skłonność do zawyżania oceny tego kąta. Przez to mamy wrażenie, że przedłużeniem lewego odcinka jest odcinek prawy górny. Można łatwo sprawdzić, mając linijkę lub inny przedmiot o prostej krawędzi, że w rzeczywistości to prawy dolny odcinek jest przedłużeniem lewego.
Przykład z iluzją Poggendorffa otwiera cały worek nowych pytań i problemów. Jak dokładnie nasz mózg jest w stanie ocenić wielkości? Czy dokładność oceny wielkości zależy od sposobu ich przedstawiania (długość linii, wielkość pola, natężenie koloru, wielkość kąta)? Czy przy względnych ocenach dokładniej odczytujemy różnice, czy ilorazy wielkości?
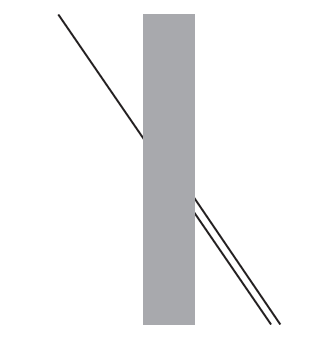 Rysunek 25: Iluzja Poggendorffa związana z trudnością w dokładnej ocenie kątów. Linia widoczna po lewej stronie jest przedłużeniem jednej z linii widocznych po prawej stronie. Której? Źródło: opracowanie na bazie wikipedii
Rysunek 25: Iluzja Poggendorffa związana z trudnością w dokładnej ocenie kątów. Linia widoczna po lewej stronie jest przedłużeniem jednej z linii widocznych po prawej stronie. Której? Źródło: opracowanie na bazie wikipedii
Co łączy dentystę i dietetyka?
O czym myślicie podczas wizyty u dentysty? Wolicie myśleć w tym momencie o swoich właśnie leczonych zębach czy o czymś zupełnie innym? Może następnym razem pomyślicie o tzw. iluzji dentystycznej? Dentyści, jak i my wszyscy, ulegają złudzeniom optycznym, w ich przypadku złudzenie to ma niestety takie konsekwencje, że czasem wiercą zbyt duże dziury w zębach swoich pacjentów (czyli w naszych)[OShea Robert, Nicholas Chandler, and Rajneesh Roy. Dentists make larger holes in teeth than they need to if the teeth present a visual illusion of size. PLoS ONE (10), 2013]
Co to znaczy? Wyobraźmy sobie, że jesteśmy dentystą i widzimy takie dwie próchnice w zębie jak na obrazku poniżej. Która jest większa? Którą należy bardziej oczyścić (czyli, w rozumieniu laika dentystycznego, rozwiercić?). Wygląda na to, że prawa jest większa, zatem należy ją bardziej rozwiercić.

Tymczasem obie czarne “dziury” są jednakowe. Jest to właśnie iluzja dentystyczna, a tak naprawdę iluzja Delboeufa (ang. Delboeuf Illusion), która polega na tym, że gdy dwa jednakowe zaciemnione koła otoczymy okręgami o wspólnym środku, to koło otoczone okręgiem o mniejszym promieniu wyda się większe. Czyli, gdy wewnętrzne koło ma promień znacząco mniejszy niż zewnętrzny okrąg, to wydaje się jeszcze mniejsze. Natomiast, gdy wewnętrzne koło ma promień nieznacznie mniejszy niż zewnętrzny okrąg, to wydaje się większe niż jest w rzeczywistości. Iluzja ta została odkryta przez belgijskiego psychoanalityka i hipnotyzera Josepha Delboeufa (1831–1896).
Iluzja Delboeufa ma również duże znaczenie dla wszystkich odchudzających się, zatem warto, aby znali ją też dietetycy. Jeżeli ktoś się odchudza i położy sobie jedzenie na mniejszym talerzu, to będzie mu się wydawało, że zjadł więcej, zatem dłużej będzie czuł się syty, bowiem wierzymy w to, co widzimy. W konsekwencji zje mniej, będzie mniej podjadał. Zasada ta jest obwarowana pewnymi dodatkowymi warunkami. Warto zadbać o zastawę w kolorach kontrastujących z obrusem, wtedy iluzja będzie silniejsza. Jednocześnie powinniśmy nałożyć na talerz jedzenie w wyraźnym kolorze. Polecany jest np. mały jasny talerz, ciemny obrus i ciemne jedzenie. W przypadku jedzenia w kolorze zbliżonym do talerza nasz mózg musi się bardziej napracować, aby ocenić wielkość porcji i powiedzieć nam “dosyć”.
Najlepsze jest to, że nasz mózg ulega tej iluzji nawet wtedy, gdy wiemy, że mamy mały talerz.
Rysunek 26: Ilustracja iluzji Josepha Delboeufa. Źródło: opracowanie na bazie wikipedii
Kolejny krąg piekieł
Opisane powyżej iluzje, takie jak pokój Amesa czy iluzja Poggendorffa, działają w podobny sposób na większość osób. Złudzenie perspektywy, czy efekty hamowania obocznego, są praktycznie takie same dla różnych odbiorców. A skoro wiemy w jaki sposób obraz jest zniekształcany, to możemy to zniekształcenie kompensować, np. sztucznie zwiększając lub zmniejszając elementy obrazu. Przykładem takiego działania są np. techniki antyaliasingu. Modyfikują one wyświetlany na monitorze obraz, tak by jego krawędzie były postrzegane jako bardziej gładkie lub bardziej ostre.
Ale obok iluzji, które działają w podobny sposób na wszystkich odbiorców, znajduje się grupa iluzji, które różne osoby będą odczytywały na różne sposoby. Obrazy z tej grupy nazywa się często obrazami dwu- lub wielostabilnymi.
Jednym z najstarszych znanych przykładów, jest przedstawiona na rysunku 27 reprodukcja niemieckiej pocztówki z roku 1888. Przedstawia ona obraz, który ma dwie różne stabilne interpretacje. Czy jest to odwrócona tyłem młoda kobieta, czy też profil starszej, uśmiechającej się kobiety? Na obrazie brakuje wskazówek, które pozwoliłyby ustalić, która z tych dwóch interpretacji jest poprawna. Całkiem prawdopodobne jest, że patrząc na ten obraz nasz mózg przez jakiś czas na zmianę będzie widział jedną i drugą interpretację, aż w końcu jedną z nich zostanie uznana za bardziej prawdopodobną. Końcowy wybór będzie jednak różny dla różnych osób, a po pewnym czasie może się różnić nawet dla tej samej osoby.
 Rysunek 27: Czy widzisz odwróconą młodą kobietę czy profil starszej kobiety? Ten sam obraz może być różnie odczytany. Źródło: Wikipedia, domena publiczna
Rysunek 27: Czy widzisz odwróconą młodą kobietę czy profil starszej kobiety? Ten sam obraz może być różnie odczytany. Źródło: Wikipedia, domena publiczna

Rysunek 28: Królik i Kaczka (niem. Kaninchen und Ente). Najstarsza znana wersja dwustabilnego obrazu przedstawiającego jednocześnie kaczkę i królika. Po raz pierwszy opublikowana przez Fliegende Blättera w roku 1892. Źródło: Wikipedia, domena publiczna
Przykładów takich wieloznacznych obrazów jest znacznie więcej. W roku 1832 Louis Necker opublikował rzut sześcianu, bez śladów perspektyw (patrz rysunek 29). Nie sposób rozstrzygnąć, która ściana sześcianu jest bliżej odbiorcy. Ale nasz mózg usilnie stara się zobaczyć trójwymiarowy obiekt, a taki musi którąś ścianę bliżej.
Najbardziej znanym obrazem wielostabilnym jest przestawiony na rysunku 28 szkic “Królik i Kaczka”. Większość dorosłych już gdzieś tę iluzję widziała, wiemy więc czego się spodziewać. Warto pokazać ją dziecku, pytając, czy szkic przypomina bardziej królika czy kaczkę. Patrząc na próby rozwiązania tego dylematu, będziemy na nowo odkrywać problemy, które niejednoznaczny obraz stawia przed naszą percepcją. Zresztą, te problemy trapią nie tylko dzieci. W literaturze można znaleźć prace naukowe, badające, czy takie czynniki jak płeć czy wiek, mogą mieć wpływ na to, że częściej widzimy kaczkę niż królika.
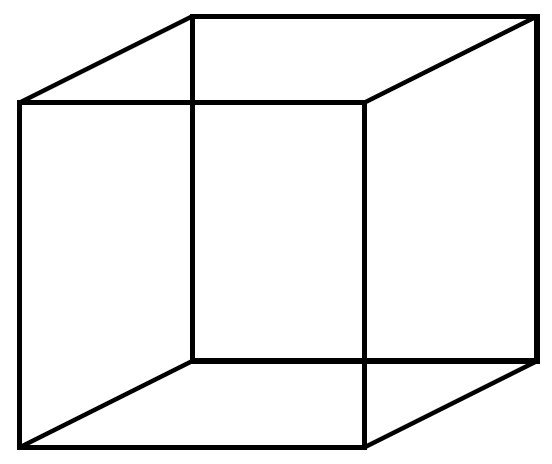 Rysunek 29: Kostka Neckera. Która ściana tego sześcianu jest bliżej? Źródło: opracowanie na bazie wikipedii
Rysunek 29: Kostka Neckera. Która ściana tego sześcianu jest bliżej? Źródło: opracowanie na bazie wikipedii
W roku 1915 Edgar Rubin opracował rysunek dwustabilny wazy/twarzy (rysunek 30). Był on punktem wyjścia do dziesiątków eksperymentów, które miały na celu zbadanie, czy poprzez zmianę kolorów lub tekstury można usunąć niejednoznaczność.
Figury wielostabilne fascynują zarówno grafików jak i psychologów. Niejednoznaczne obrazy, który mają kilka alternatywnych interpretacji, są ciekawe poznawczo i pozwalają tworzyć ciekawe eksperymenty. A jakie konsekwencje taki obraz ma dla nas, twórców wykresów? Jeżeli elementy wykresu są wieloznaczne, jest prawdopodobne, że znajdą się osoby, które odczytają wykres inaczej niż to sobie zaplanowaliśmy. Unikajmy więc jakichkolwiek niejednoznaczności na wykresach.
 Rysunek 30: Waza Rubina. Czy to waza, czy może jednak dwie skierowane ku sobie twarze? Źródło: Wikipedia, domena publiczna
Rysunek 30: Waza Rubina. Czy to waza, czy może jednak dwie skierowane ku sobie twarze? Źródło: Wikipedia, domena publiczna
Ocena wielkości
Problemów z percepcją wielkości jest więcej. Przykładowo, jeżeli chcemy pokazać, że produkcja piwa w kraju A jest dwa razy większa niż w kraju B i chcielibyśmy przedstawić wielkość produkcji za pomocą wielkości kufla piwa, to szybko okaże się, jak trudne jest to zadanie.
Jeżeli każdy z trzech wymiarów drugiego kufla zwiększymy dwukrotnie w stosunku do wymiarów pierwszego kufla, to objętość wzrośnie ośmiokrotnie. Jeżeli wymiary kufla zwiększymy 1,26 razy w każdym wymiarze, to objętość będzie dwa razy większa. Ale nasza percepcja nie potrafi oszacować dobrze ani objętości trójwymiarowych obiektów, ani ich dwuwymiarowych rzutów. Rzeczywisty dwukrotny wzrost objętości odbierzemy jako wzrost o 50%–90% rzeczywistego wzrostu (różne osoby odczytają to różnie, o czym napiszemy później). Jakie jest wyjście z tej sytuacji? Znając ograniczenia naszej percepcji, najlepszym wyborem jest po prostu nie używać objętości do reprezentacji liczb.
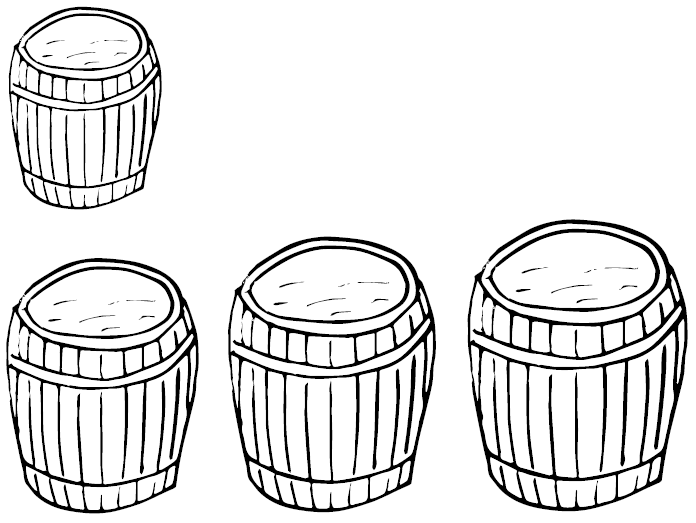
Wielu badaczy interesowało się tym problemem. Pierwszą z prac poświęconą percepcji wielkości aspektów używanych na wykresach była praca The Visual Decoding of Quantitative Information on Statistical Graphs [Journal of the Royal Statistical Society Series A,
150:192--229, 1987]
Jej autorzy po przeprowadzeniu zbioru eksperymentów przygotowali hierarchię charakterystyk uwzględniającą precyzję odczytywania wartości.
Rysunek 27: Która z trzech poniższych beczek jest dwa razy większa niż beczka u góry? Źródło: opracowanie własne
Zgodnie z tą hierarchią precyzja odczytywania charakterystyk wielkości jest ułożona od najdokładniej odczytywanych do najmniej zgodnie z następującą listą:
pozycje obiektów rozmieszczonych wzdłuż wspólnej skali (przykładowo wykres punktowy),
pozycje obiektów wzdłuż takiej samej, ale nie wspólnej skali (przykładowo sąsiadujące wykresy punktowe),
długości odcinków rozmieszczonych wzdłuż wspólnej skali,
długości odcinków wzdłuż takiej samej, ale nie wspólnej skali (o rożnych punktach zaczepienia),
wielkości kątów i nachylenia (przy ocenie tempa wzrostu w wykresach liniowych),
powierzchnie,
objętości, gęstości, natężenia koloru,
sama barwa koloru.
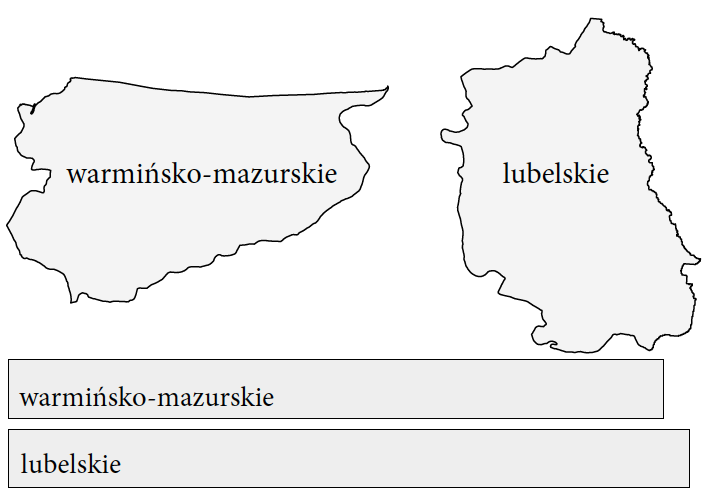
Rysunek 28: Które województwo jest większe i o ile? Różnice w wielkości znacznie łatwiej zauważyć, gdy są przedstawione jako długości odcinka, niż nierównomierne powierzchnie. Województwo lubelskie ma powierzchnię 25 133 km2, a województwo warmińsko-mazurskie ma powierzchnię 24 173 km2. Źródło: opracowanie własne
Inni badacze próbowali scharakteryzować zdolność do względnego wykrywania różnic w wielkościach. Metodologicznie jest to bardzo ciekawy problem. Jeszcze w XIX wieku badania na ten temat prowadził Ernst Heinrich Weber (1795–1878). Zaobserwował on, że dokładność, z jaką rozróżniamy wielkości, jest proporcjonalna do danej wielkości. Czyli jeżeli jesteśmy w stanie rozróżnić ciężar dwóch przedmiotów o wadze 100g i 105g, to proporcjonalnie rozróżnimy z podobną pewnością przedmioty o wagach 200g i 210g. Innymi słowy, prawdopodobieństwo $p$ wykrycia różnicy o $\delta x$ zależy od $x$ w następujący sposób $$ p = k \frac{\delta x}{x}, $$ gdzie $k$ to pewna stała zależna od sposobu przedstawiania wartości (to prawo działa tylko dla małych $\delta x$). Inną stałą będziemy mieć, gdy wartości będziemy przedstawiać za pomocą długości linii ($k$ duże, duża precyzja) inną, gdy za pomocą objętości ($k$ małe, mała precyzja). Możemy więc eksperymentalnie i ilościowo mierzyć jak dobre są określone środki przedstawiania wielkości, szacując na podstawie badań wielkość $k$ eksperymentalnie.
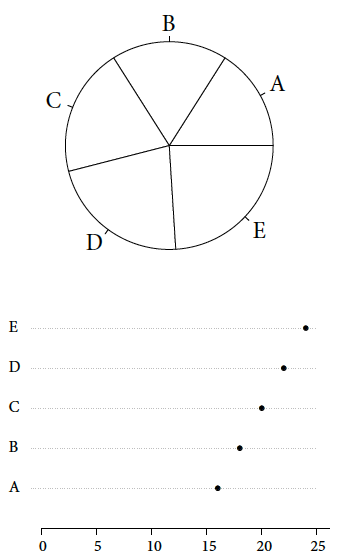 Rysunek 29: Na obu wykresach przedstawiono te same wartości, a jednak łatwość wskazania która z wartości jest największa, a która najmniejsza jest zupełnie inna. Dla wykresu kołowego trudno jest jednoznacznie określić porządek wartości A–E. Źródło: opracowanie na bazie przykładu podanego przez Clevlanda
Rysunek 29: Na obu wykresach przedstawiono te same wartości, a jednak łatwość wskazania która z wartości jest największa, a która najmniejsza jest zupełnie inna. Dla wykresu kołowego trudno jest jednoznacznie określić porządek wartości A–E. Źródło: opracowanie na bazie przykładu podanego przez Clevlanda
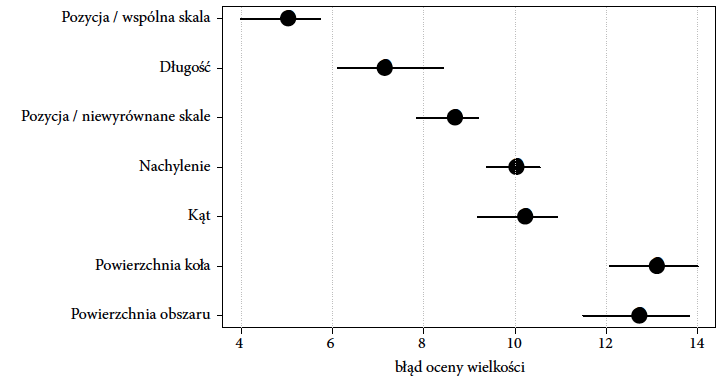
Jeszcze innym podejściem do tematu analizy odbioru bodźców są badania prowadzone przez Stanleya Smitha Stevensa (1906-1973) w połowie XX wieku. Zaproponował on prawo potęgowe, zgodnie z którym względny iloraz wielkości pomiędzy dwoma bodźcami $x_1/x_2$ odczuwamy z siłą $\phi$. Zależność tę opisuje równanie $$ \phi = C \left(\frac{x_1}{x_2}\right) ^ \beta, $$ gdzie $C$ to w tym przypadku nieistotna stała, a $\beta$ odpowiada “zakrzywieniu” skali, w jakiej występują obserwowane bodźce względem skali, w jakiej je postrzegamy. Przykładowo, dla większości ludzi długości linii są postrzegane ze współczynnikiem $\beta$ w granicach 0,9–1,1. Czyli widząc jedną linię dwa razy dłuższą od drugiej, odbierzemy względną ich długość w miarę poprawnie. Jednak w przypadku powierzchni ten współczynnik oscyluje (różni się dla różnych osób) w granicy 0,6–0,9. Oznacza to, że widząc dwa kwadraty, jeden o polu dwa razy większym niż drugi, ocenimy powierzchnię drugiego kwadratu jako większa o około 75%. Jeszcze większe zniekształcenie występuje, gdy mamy do czynienia z obiektami różniącymi się objętością, w tym przypadku $\beta$ jest w przedziale 0,5–0,8 (pamiętasz Czytelniku wcześniejszy przykład z beczkami?).
Rysunek 30: Średnie błędy percepcji w odróżnianiu wielkości różnych obiektów. Źródło: opracowanie na bazie wyników Clevelanda i McGilla

Jeszcze większe zniekształcenia dotyczą natężenia kolorów. Gdy oceniamy względne natężenia szarości, współczynnik $\beta$ waha się w okolicach 0,5 (potrzebne jest więc czterokrotnie większe natężenie bodźca, by odebrać go jako wzrost dwukrotny), ale jeżeli oceniamy natężenie czerwieni, współczynnik $\beta$ przyjmuje wartości ponad 1,5.
Wnioskiem z tych badań jest więc, że jeżeli chcemy pokazywać względne wielkości, to najlepiej używać takich charakterystyk jak długość i trzymać się z daleka od pól, objętości i nasycenia kolorów. Niestety, często nie zważa się na te badania i dlatego spotykamy kolory i powierzchnie razem używane do przedstawiania wielkości.
Rysunek 31: Dwie skale przedstawiają natężenie szarości od koloru białego do czarnego. Na dolnej skali natężenie czerni zmienia się liniowo, jednak nasza percepcja powoduje, że z dużą czułością widzimy różnice pomiędzy białą kratką a najjaśniejszym szarym kolorem, a znacznie mniej wyraźna jest różnica pomiędzy kolorem czarnym a kolorem go poprzedzającym. Skala u góry została dopasowana tak, by nasza percepcja widziała te kolory jako liniowo rozmieszczone w skali percepcji, w rzeczywistości odpowiadają one jednak nieliniowemu natężeniu szarości
Wybiórcza uwaga i niewidoczne zmiany
W poprzednich rozdziałach pokazaliśmy jak wiele problemów w analizie danych dostarczyć może tylko jeden wykres (zagadnienia koloru, wielkości, kątów). Okazuje się, że problemy zaczną się mnożyć, jeżeli mamy do czynienia z animacją. Większość osób lubi oglądać animacje, ponieważ poruszające się obiekty przykuwają uwagę. Rodzi to pokusę, by wykorzystać animacje do prezentacji danych.
Pamiętajmy jednak, że nasz wzrok jest w stanie analizować jedynie ograniczony obszar. Jeżeli będziemy patrzeć na coś innego niż to, co jest ważne, możemy całkowicie nie dostrzec zależności, którą chcemy podkreślić.
Interesującą ilustracją tego zjawiska jest eksperyment nazywany “niewidzialnym gorylem” [Perception, 28:1059--1074, 1999] Osoby, które nie znają tego doświadczenia, a lubią eksperymentować, powinny w tym miejscu przerwać czytanie i wyszukać odpowiedni film wpisując na portalu youtube.com hasło “Selective attention test”. Należy postępować zgodnie z instrukcjami lektora, a po obejrzeniu filmu wrócić do czytania reszty tego podrozdziału
Dla osób, które nie mają dostępu do internetu, krótkie streszczenie. Eksperyment jest następujący. Oglądający film zostali poproszeni o zliczenie liczby podań piłki, w którą grała grupa osób na filmie. Koncentrując całą uwagę na śledzeniu piłki, większość obserwujących film nie dostrzega osoby w przebraniu goryla, która przechodzi przez środek pokoju, bijąc się na środku w piersi. Wiedząc, czego możemy się spodziewać, dostrzeżemy tego goryla. Prawdopodobnie również będziemy mieć problem z uwierzeniem, że można go było nie dostrzec. Goryl jest wielki i bardzo wyróżnia się na tle grających. W tym przypadku warto znaleźć kogoś, kto o selektywnej uwadze nie słyszał i przeprowadzić na nim eksperyment z gorylem.
W internecie znaleźć można więcej przykładów eksperymentów ilustrujących “wybiórczą uwagę” lub “wybiórczą ślepotę”. Wszystkie one są potwierdzeniem faktu, że animacja nie nadaje się do przekazywania złożonych informacji. Jeżeli koniecznie chcemy zbudować animowany wykres, to musimy się zatroszczyć o to, by obserwator wiedział, na jaki element obrazu ma patrzeć.


Rysunek 32: Zdjęcie z filmu ilustrującego eksperyment “niewidzialny goryl”. W filmie przez środek pokoju powoli przechodzi goryl, jednak z uwagi na obciążenie poznawcze związane z liczeniem podań piłki część obserwatorów go nie zauważa. Patrząc na to zdjęcie, aż trudno w to uwierzyć. Źródło: korespondencja z Danielem Simonsonem
Na co uważać, czego używać?
Poznaliśmy wiele przykładów, w których stary oszust, czyli nasz układ wzrokowy widział rzeczy, których nie było, zawyżał lub zaniżał kąty, pola, kolory lub nie widział rzeczy, wydawałoby się bardzo widocznych, takich jak goryl maszerujący przez pokój.
Może więc lepiej pozostać przy opisie słownym zależności w danych? Nie ryzykować przekłamania, pozostać przy może i długim, może i abstrakcyjnym opisie, ale takim, który trudno źle odczytać?
Moim zdaniem, warto wykorzystać superkomputer, który analizuje obraz w naszym mózgu. Trzeba to tylko zrobić ostrożnie. Najlepiej stosując się do trzech prostych zasad. Te trzy proste zasady, pozwolą na tworzenie wykresów znacznie bardziej czytelnych niż 90% tego, co znaleźć można obecnie w mediach.
Przedstawiać tylko to, co jest istotne Im więcej elementów na wykresie, tym trudniej będzie w tym bałaganie odnaleźć odbiorcy właściwy sygnał. Pseudo trzeci wymiar nic nie wnosi, a nawet jeżeli coś wnosi, to zazwyczaj i tak będzie to źle odczytane. Upiększanie wykresu przez dodawanie niepotrzebnych kolorów czy innych ozdobników również utrudnia odnalezienie tego, co na wykresie jest ważne. Złota zasada KISS (ang. keep it simple, stupid), która bywa tłumaczona na polski jako BUZI (Bez Udziwnień Zapisu, Idioto), ma w tym miejscu zastosowanie.
Używać charakterystyk, które umysł odczytuje precyzyjnie Nie wszystkie charakterystyki są równe w prezentacji informacji. Nasz mózg całkiem przyzwoicie odgaduje proporcje długości, gorzej radzi sobie z proporcją regularnych kształtów, takich jak okręgi czy kwadraty, ale zupełnie nie radzi sobie z odgadywaniem pól nieregularnych kształtów, wycinków koła, kątów. Jeżeli zależy nam na tym, by proporcje zostały poprawnie odczytane, używajmy narzędzi, które to umożliwiają. Kolory czy kształty mogą być użyteczne, ale do innych celów niż przedstawianie wartości liczbowych (chyba, że wiemy co robimy – patrz kolejny esej).
Krytycznie weryfikować to, co widać na wykresie Jako twórcy wykresu zazwyczaj wiemy, co chcemy pokazać. Wiemy, na co patrzeć i jak to coś odczytać. Niestety odbiorca wykresu może nie mieć tej wiedzy patrząc na wykres po raz pierwszy. Dlatego warto krytycznie spojrzeć na wydrukowane wykresy, pytając siebie lub jeszcze lepiej osobę postronną ze świeżym spojrzeniem, co na danym wykresie widać, a czego nie widać. Z czasem nauczymy się patrzeć na własne wykresy z cudzej perspektywy, ale na początku, pomoc innych osób jest nieoceniona. Pamiętajmy jak bardzo to, co widzimy, jest zaburzone przez to, co chcemy zobaczyć, czego szukamy i czego się spodziewamy.
Udostępnione na licencji Creative Common BY & SA ![]()


Przemysław Biecek, Odkrywać! Ujawniać! Objaśniać! Zbiór esejów o sztuce przedstawiania danych,
Fundacja Naukowa SmarterPoland.pl, Warszawa 2016, ISBN 978-83-65291-05-9